
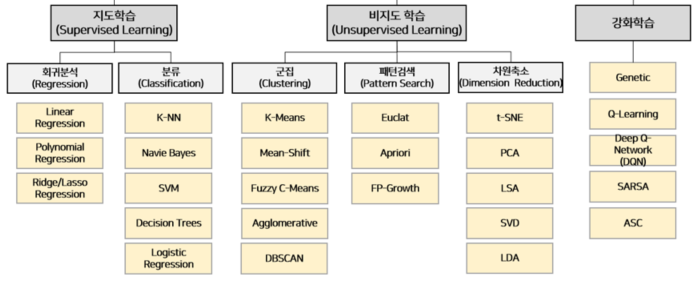
머신러닝이란?

분류알고리즘
연속적인 값의 벡터를 입력하여 이산적인(discrete, 0 또는 1) 하나의 클래스 값을 주는 것
분류 모델을 평가하기 위해 사용되는 지표
- ROC curve
- F1 score
- Confusion matrix: 재현율(recall), 정밀도(precision), 정확도(accuracy)를 구할 수 있다.
- 재현율: TP / (TP + FN), 모든 관련있는(relevant)데이터의 비율
- 정밀도: TP / (TP + FP)
- F-measure: 2 * (재현율 * 정밀도) / (재현율 + 정밀도)
로지스틱 회귀(Logistic Regression)
분류를 확률로 생각하는 방식, 시그모이드 함수


서포트 벡터 머신(Support Vector Machine)
클래스를 분류할 수 있는 다양한 결정 경계(decision boundary, hyper plane)이 존재하며 마진이 가장 큰 경계가 최적의 경계이다.
판별 분류기(discriminative classifier)
커널(Kernel)
고차원 공간으로 변환하여 결정 경계 찾는 역할을 함
데이터 간의 유사성 측정 가능
커널의 종류에는 선형, 다항식(Polynomial), 가우시안(Gaussian), 시그모이드(Sigmoid)가 있다.


나이브 베이즈(Naive Bayes)
베이즈 정리를 활용하여 만들어진 분류 알고리즘
텍스트 분류에 적합함, 무작위로 분포된 데이터셋에 적합함
발생할 사건들을 미리 입력시킨 후, 후에 정보가 들어오면 예측
나이브 베이즈를 통한 가정이 사실일 수도 있고, 거짓일 수 도 있기 때문에 베이즈 앞에 나이브가 붙음
P(A | B) = P(A) * P(B | A) / P(B)
KNN(K-Nearest Neighbor)
주변 이웃 데이터들의 특징을 파악하고 가장 유사한 데이터 그룹에 포함되도록 하는 방식
유클리드 거리 또는 맨헤튼 거리 계산법을 통해 가까운 이웃을 찾음
Lazy learning ( 게으른 놈 )

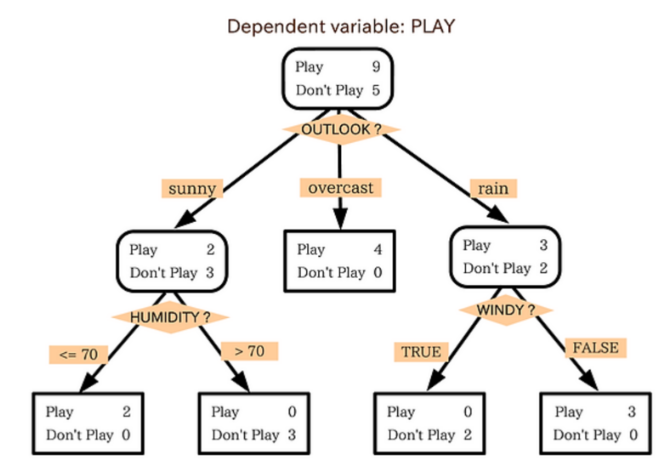
의사결정 트리(Decision Tree)
질문을 던져서 맞고 틀리는 것에 따라 좁혀나감
최소한의 엔트로피로 최대한의 정보를 빼내기
의사결정 트리의 과적합 문제를 해결하기 위해, 의사결정 트리를 여러개 만들어서 Random forest로 진화!
회귀 알고리즘
연속적인 출력값을 예측
MAE(Mean Absolute Error)
실제 값과 예측 값을 가지고 구한 평균 절대 오차 ( |실제값 - 예측값| )
Normal Equation
선형 회귀 문제를 푸는 Closed-form 해법 중 하나
반복과 학습률 없이 해를 구할 수 있고, 특성의 수가 많아지면 계산속도가 느려질 수 있다.
단순 선형 회귀(Simpe Linear Regression)
회귀계수가 선형이며 독립변수를 1개 가지는 회귀이다.
이상치(outlier)에 민감하다.
손실이 생긴다.
입력값을 1만큼 변경하면 기울기(slope parameter)만큼 증가한다.

잔차
실제 값과 모델이 예측한 값의 차이를 잔차라 한다. (실제 - 예측)
데이터 포인트와 회귀선 사이의 수직선(perpendicular line)
경사 하강법(Gradient Descent)
손실함수를 최소화하는 방식
최소제곱오차(Least Square Error)를 활용하여 최적의 직선을 찾는다.

다중 선형 회귀(Multiple Linear Regression)
두 개 이상의 독립변수를 가지는 회귀

다항 회귀(Polynomial Regression)
독립 변수가 여러개인 다항식 형태의 회귀

로지스틱 회귀(Logistic Regression)
종속변수가 이상변수인 경우에 사용되는 회귀

서포트 벡터 회귀(Support Vector Regression)
SVM을 회귀 문제에 적용한 것
허용오차를 epsilon(엡실론) 이라 하며, 훈련 데이터와 예측값 사이의 차이가 epsilon보다 작아지도록 학습
의사결정 트리(Decision Tree)
데이터셋을 분할하는 기준으로 정보 엔트로피(Infomation Entropy)와 정보 이득(Infomation Gain)을 사용한다.
정보 엔트로피는 데이터셋의 혼잡도를 나타낸다.
정보 이득은 데이터셋을 분할했을 때, 전후의 엔트로피의 차이를 나타낸다.
자연어 처리 과정
1. 문장분리
2. 토큰화(Tokenization)
3. 불용어 제거(Stopword Removal)
4. 어간추출(stemming) 또는 원형추출(lemmatization)
